.png)
Binary Classification Scoring Methods(2)
지난 시간엔 정답의 형태에 따른 예측 문제의 구분을 알아보았다.
(지난 게시물-Scoring Methods over Binary Classification Problem(1))
그리고 이진분류 예측문제에서 학습된 머신러닝 모델이 얼마나 예측값을 잘 나타내고 있는지 판별할 수 있는 점수에 대해서도 알아 볼 수 있었다.
그러나 정확도는 완벽한 점수라고 하기엔 데이터 편향성에 따른 약점이 존재하였고, 보다 데이터를 디테일하게 확인할 수 있는 혼동행렬에 대해서도 알아보았다.

혼동행렬은 그 자체로 평가 기준이 될 수 있지만 단일값으로 나타낼 수 없다는 단점이 있다.
하지만 단일값들로 나타낼 수 있는 다른 평가점수들을 알기쉽게 표현할 수 있다는 장점도 가지고 있다.
오늘은 그러한 단일값으로 나타나는 다른 평가점수들을 알아보겠다.
이진분류문제, 즉 Positive(1), Negative(0)인 문제라고 생각해보자.
- Positive : 1
- Negative : 0
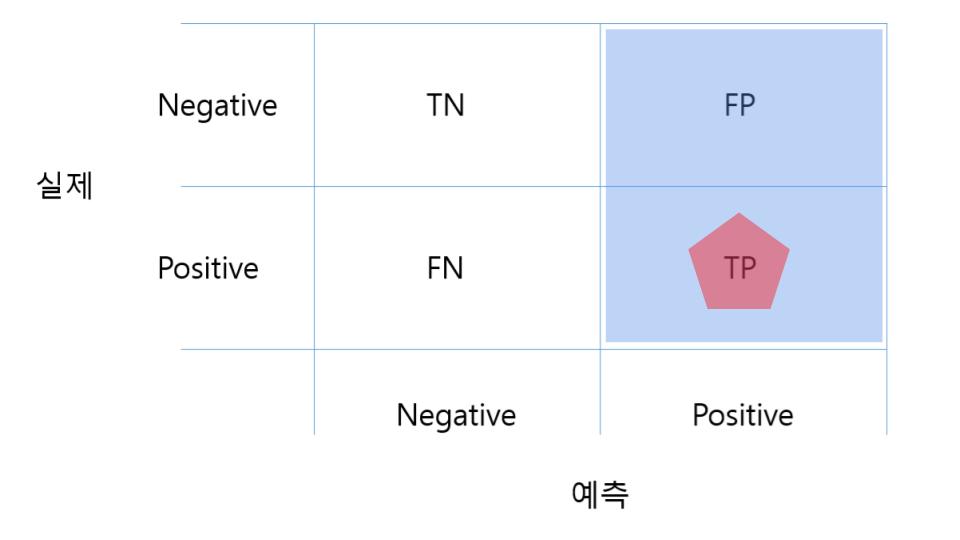
Precision (정밀도)
정밀도는 머신러닝 모델이 1이라고 예측한 것 데이터 중 실제로 1인 데이터의 수 이다.
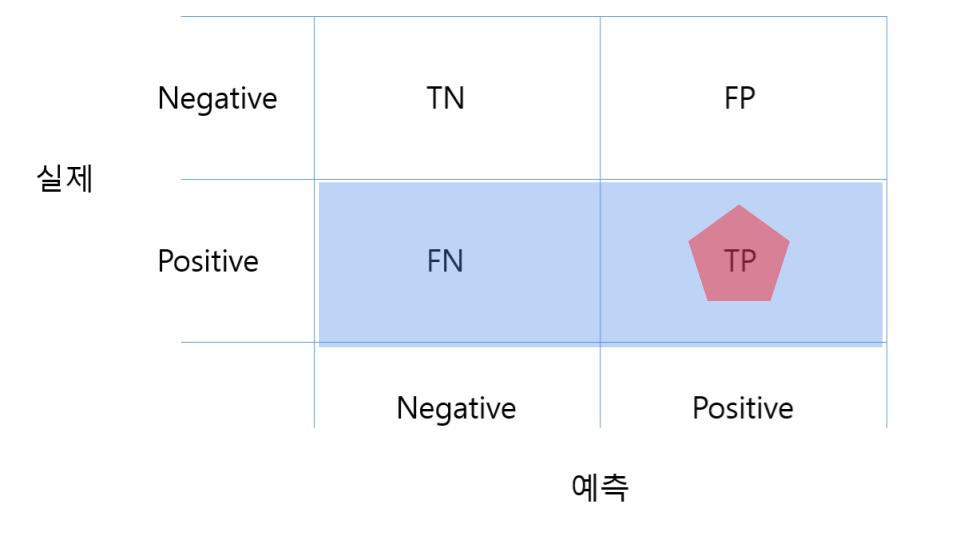
Recall (재현율) = Sensitivity (민감도)
재현율(또는 민감도, 둘은 이음동의어다)은 실제 1인 데이터 중 머신러닝모델이 1이라고 예측한 데이터의 수 이다.
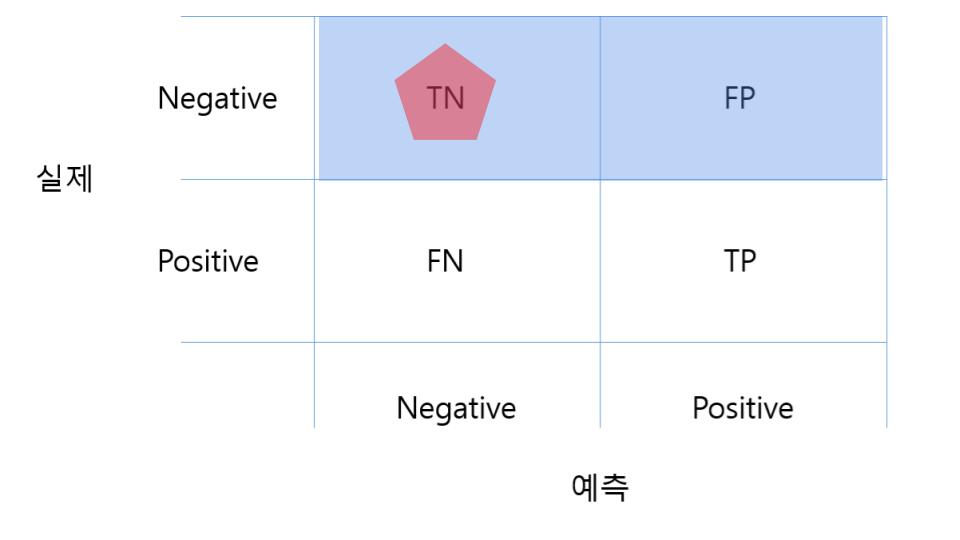
Specificity (특이도)
특이도는 실제 0인 데이터 중 머신러닝모델이 0이라고 예측한 데이터의 수 이다.
F1 Score
F1 Score는 실제 정밀도와 재현율(민감도)의 조화평균이다.
F1 score는 정밀도와 재현율이 비슷할 때 점수가 크다. 하지만, 상황에 따라 정밀도와 재현율의 중요도가 다를 수 있으므로, 자신의 문제에서 무엇이 더 중요한 지 생각해 보아야 한다.
끝
Comments