.png)
머신러닝 #1. Decision Tree, Random Forest, Gradient Boosting Machine
파이썬에서 머신러닝을 배운다치면 무조건 거쳐가는 Scikit Learn(흔히 패키지명으로 Sklearn)이라는 머신러닝 필수패키지가 있다.
바로 그 핵심개발자가 쓴 파이썬 라이브러리를 활용한 머신러닝(O’REILLY(오라일리)) 라는 책의 내용을 바탕으로 머신러닝 관련 첫 게시물을 쓰고자한다.
책 내용은 정말 핵심들 위주로 잘 쓰여져 있으며, 무엇보다도 저자의 목표자체가 쉬운 머신러닝 (초심자도 쉽게 접할 수 있는 머신러닝)에 초점을 맞추고 있어 정말로 쉽고 간결한 호흡으로 읽을 수 있어 마음에 쏙 드는 책이다.
오늘 내용은 알고리즘의 기초원리나 실습코드를 주로 확인하기보다는 알고리즘별 사용되는 중요한 패러미터라던지, 알고리즘을 운용할때의 팁들에 대해서 정리하는 등 두서없는 메모의 형태로 작성하고자하니, 혹시 읽으시는 분들은 참고해주시길 바란다.
Decision Tree (의사결정나무, 디시전 트리)
1) 개요
- 분류와 회귀, 모두 사용이 가능하다.
- 책에서 디시전 트리를 가르켜,
스무고개 놀이에 비유한다. 바로 어떠한 정답을 찾아나가는데 있어 질문들을 하나씩 만들어 Yes/No로 구분하면서 생겨나가는 분기점들을 모아서 하나의 나무로 그려내는 것이 디시전 트리라고 할 수 있다.

(출처)
2) 내가 놓치고 있던 내용/셀프 궁금증
-
디시전 트리가 생성되고 데이터를 계속 분할해 가는데, 최종 노드인 리프노드에서 한 개의 타겟값을 가지게되면, 바로 이 리프노드를 순수노드(Pure Node)라고 부른다.
- 회귀문제에 적용될 때에는 노드의 테스트 결과에 따라 데이터가 트리를 탐색 > 새로운 데이터 포인트에 해당되는 최종 리프 노드 발견 > 해당 리프 노드의 훈련 데이터 평균값을 결과값으로 산출
?그 평균값이라는 것은 산술평균일까 기하평균일까 조화평균일까? 그것을 패러미터 옵션으로 지정할 수 있을까?
- 디시전 트리는 훈련셋을 최대로 학습시키면 모델이 매우 복잡해진다. 그리고 이것은 과적합(Overfitting) 문제를 야기한다. 이러한 과적합을 방지하기 위한 트릭이 바로
Pruning(가지치기)이다.Sklearn 의 디시전 트리 가지치기 패러미터 : max_depth, max_leaf_nodes, min_samples_leaf. (이 가운데 하나만 지정해도 효과를 볼 수 있다)
- 가지치기 방법의 종류는 트리 생성을 조기에 중단하는
Pre-Pruning(사전가지치기)와 트리를 다 만들고나서 데이터포인트가 적은 노드를 삭제하거나 병합하는Post-Pruning(사후가지치기)가 있다.Scikit Learn에서는
사전가지치기만 지원한다고 한다. - 완성된 디시전 트리가 어떻게 작동하는지 0과 1사이 값으로 요약하는 대표적인 속성이
특성 중요도(feature Importance)이다.0과 1사이 값으로 표현되며, 단순회귀분석에서 지원되는 변수의 음수관계(-)가 여기서는 표현되지 않는다.
- 특성 중요도는 0일때 전혀 사용되지 않았으며, 1일때 완벽하게 타깃 클래스를 예측했다는 뜻이다. 특성 중요도의 전체 합은 1이다.
?지니계수(Genie)를 사용해서 엔트로피값을 정리해가며 그 중요도를 계산하는 수작업을 해본듯한 기억이 날듯말듯하다. 맞는지 팩트체크 요망.
-
단, 특정 특성(피쳐)의 중요도 값이 낮다는 말이 이 특성이 유용하지 않다는 의미는 아니다. (단지 이번에 만들어진 트리에서는 그 특성을 선택하지 않았으며, 이는 랜덤한 결과값 혹은 다른 특성(피쳐)가 동일한 정보를 가지고 있기 때문일 수도 있다.)
- 디시전 트리를 회귀문제에 적용시, ** 외삽(Extrapolation) ** 이슈가 발생한다. 이는, 디시전 트리가 훈련셋 범위 밖의 포인트에 대해 예측값을 내놓을 수 없다는 이슈이다.
해당 문제로 인해, 디시전 트리는 시계열 데이터(특히 바로 다음 시점에 기존과 전혀다른 값이 발생할 가능성이 있는)에는 잘 맞지 않는다는 점을 잘 기억해두어야 한다.
3) 장점과 단점
- 장점
– 디시전 트리는 쉽게 시각화 할수 있으며, 비전문가도 이해하기 쉽다. (특히 작은 트리로 나타냈을 때)
– 데이터 스케일링이 필요없다. (각 특성이 개별처리되어 데이터를 분할하기 때문에, 특성의 정규화나 표준화 같은 전처리가 필요없다)
- 단점
– 사전가지치기를 사용해도 과적합 문제가 발생하는 경향이 있다 > 일반화 성능이 좋지 않다. ( > 이로인해 앙상블 방법을 도입하여, 여러 디시전 트리(Weak Learner)를 조합하여 결과를 내는 알고리즘이 대두됨)
Random Forest (랜덤포레스트)
1) 개요
- 여러개의 디시전 트리를 만들어, 그 결과를 평균냄으로써 결과를 내는 알고리즘.
- 이름도 잘 지었다고 생각되는게, 랜덤하게 심은 수 많은 디시전 트리(나무+나무 = 숲 = Forest)를 직관적으로 명명하고있다.
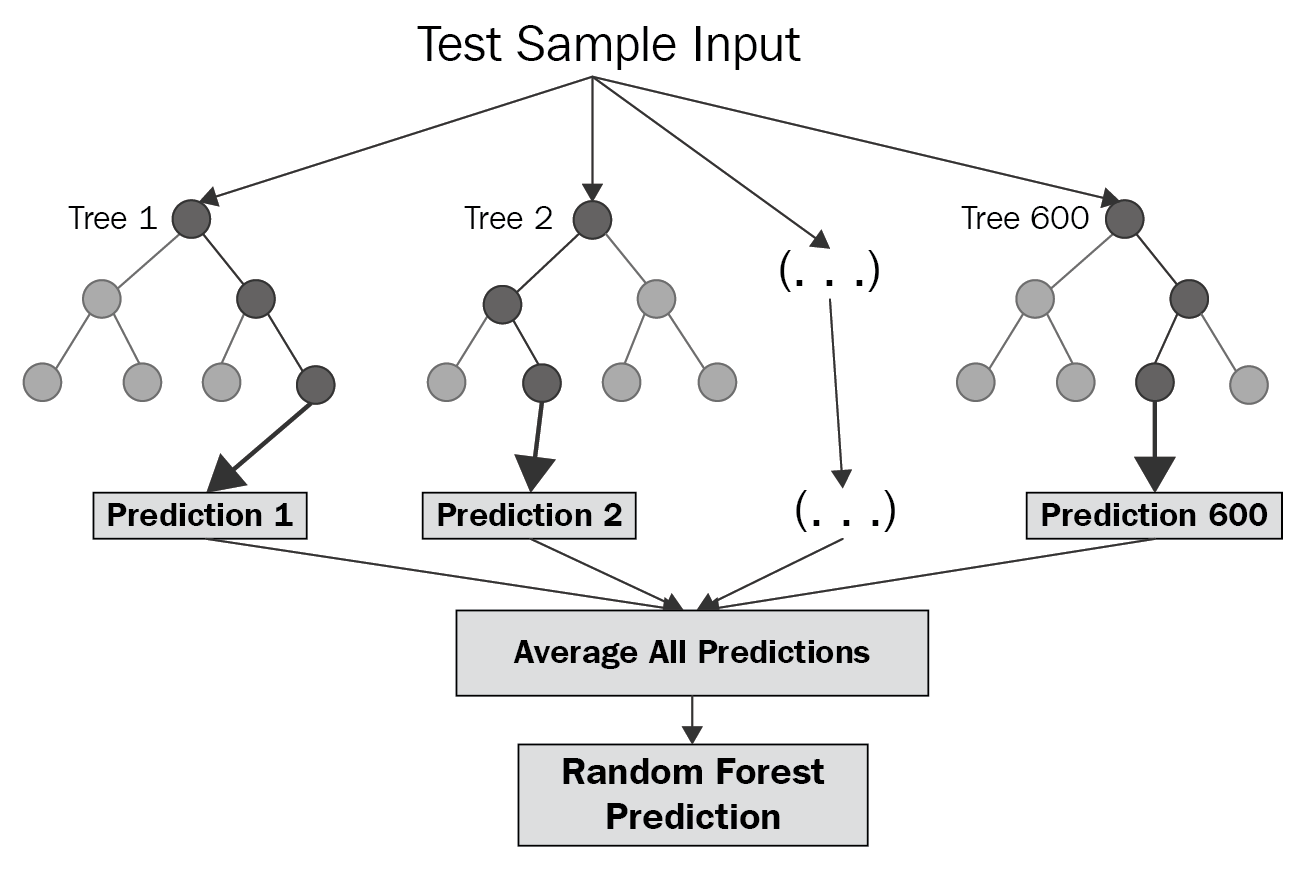
(출처)
2) 내가 놓치고 있던 내용/셀프 궁금증
-
이렇게 앙상블 방법을 도입하면 트리 모델의 예측 성능을 유지하며, 과대적합이 수학적으로 줄어듦이 증명되었다고한다.
-
이러한 앙상블의 전략이 제대로 먹혀들기 위해서는 디시전 트리를 많이 만들어야 한다. 그와 동시에 각 트리는 다른 트리와 구별되어야 한다.
-
다른 트리들과 구별되기 위해 사용하는 방법이 바로 Random(무작위성)이다. 랜덤포레스트에서는 트리 생성 시 무작위성을 2가지 방법으로 도입하고 있다.
- 트리를 만들때 사용되는 데이터포인트를 랜덤하게 선택하기 > 랜덤 데이터포인트
- 분할 테스트에서 특성(피쳐)를 무작위로 선택하기 > 랜덤 피쳐스플릿
- 랜덤 데이터포인트를 위해 먼저 Bootstrap Sample(부트스트랩 샘플)을 만든다.
n_samples패러미터 값 만큼, 전체 데이터 포인트를 반복 추출한다 (중복허용 > 최종적으로 볼때 선택이 되지 않는 데이터 포인트가 있을 수 있다! 그리고 중복되는 것도!) - 랜덤 피쳐스플릿은 전체 특성 중에서 최선의 특성들을 골라내는 것이 아니라, 몇 개의 특성들을 뽑아낸 뒤 그것으로 디시전 트리를 만든다.
max_features패러미터 값만큼, 랜덤하게 후보 특성셋을 구성하고 > 이 후보 특성셋으로 최적의 테스트를 통해 디시전 트리를 만드는 것. - 랜덤 데이터포인트와 랜덤 피쳐스플릿 중 핵심 매개변수는 랜덤 피쳐스플릿에 영향을 미치는
max_features이다.
max_features패러미터 값을 크게하면(최대 특성 개수만큼 지정하면?) > 전체 특성 셋에서 최선의 디시전 트리들이 생겨남 > 다 비슷비슷한 트리들이 생겨남 > 랜덤포레스트의 전략 훼손
max_features패러미터 값을 작게하면(최소 1개만 지정하게되면?) > 각 트리의 분기가 무작위로 선택된 한 개 특성의 임계값이 골라진다 > 완전 다른 무작위 트리들이 생겨남 > 랜덤포레스트의 전략 보존, 단, 각 트리가 데이터에 맞추기위해 깊어짐 > 학습시 계산이 복잡/시간이 오래걸리게 될지도
- 랜덤포레스트도 단일 디시전 트리처럼 특성 중요도를 산출할 수 있다.
그리고 그 중요도 값은 단일 디시전 트리보다 더 신뢰할만하다. (일반화되었으니까)
- CPU 코어가 많다면 병렬처리를 통해 코어 개수에 비례해서 빨라지는 효과 누릴 수 있다.
n_jobs=-1통해 최대 cpu개수 사용가능 -
랜덤한 방식이기 때문에,
random_state값을 지정해서 동일한 결과값을 불러내야함 -
주요 매개변수는
n_estimators, max_features, max_depth, 뒤의 2개는 사전가지치기 옵션이다. n_estimators는 값이 클수록 좋다. 더 많은 트리를 평균냄으로써 과대적합을 줄여 더 안정적이고 일반적인 모델을 만들 수 있음 > 단, 이로인해 더 많은 메모리와 긴 훈련시간 비용이 발생한다따라서
n_estimators는 가용한 시간과 메모리만큼 많이 만드는게 좋다.max_features는 각 트리가 얼마나 무작위가 될지를 결정하며, 작을 수록 과대적합을 줄여준다.
일반적으로 기본값을 쓰는게 좋음
분류에서는 기본값 :
max_features = sqrt(n_features)
회귀에서는 기본값 :
max_features = n_features
3) 장점과 단점
- 장점
– 디시전 트리의 장점을 그대로 가지고, 단점은 보완
– 성능이 뛰어남
– 패러미터를 많이 튜닝하지 않아도 잘 작동함
– 데이터 스케일링이 필요없다
- 단점
– 간소하게 보여주고 싶을때는 단일 디시전 트리로 보여주는게 덜 복잡하게 표현할 수 있음
– 텍스트 데이터와 같이 매우 차원이 높고 희소한 데이터에는 잘 작동하지 않음 (이건 선형모델이 더 적합함 > 선형모델 대비 더 많은 메모리와 훈련/예측이 느림)
Gradient Boost (그레디언트 부스트, GBM)
1) 개요
- 여러 개의 디시전 트리를 묶어 강력한 하나의 모델을 만드는 방식
- 앞서 랜덤포레스트가 디시전 트리를 병렬로 모아서 투표를 하는 방식이라고 한다면, GBM은 직렬로 세워서 모델을 발전시키는 방식
(으로 이해하고 있음) - 랜덤포레스트의 무작위성이 없는 대신, 강력한 사전 가지치기(Pre-pruning)가 사용됨
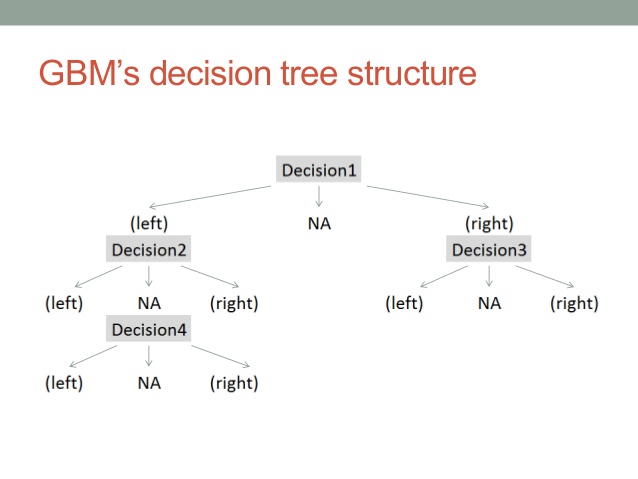
(출처)
2) 내가 놓치고 있던 내용/셀프 궁금증
- 사전 가지치기, 트리 개수(n_estimators), learning_rate(학습률)이 주요 패러미터
n_estimators 값이 커지면, 디시전 트리 모델이 더 많이 추가되어 모델 복잡도가 커지고,정교한 모델이 됨 > 달리말하면, 과대적합될 위험성이 증가함
또한 learning_rate 값이 커지면 트리에 대한 보정이 강하게 이루어져 모델이 복잡해진다
-
가용한 시간과 메모리 한도를 고려한 **n_estimators **의 값을 맞추고 나서 > 적절한 ** learning_rate **를 찾는 방법이 일반적
- 훈련 세트에 대한 과대적합을 막기위해서는 트리의 최대 깊이(max_depth)를 줄여 사전 가지치기를 강하게 하거나, 학습률을 낮추어 조절할 수 있다.
모델의 복잡도를 낮추고, 모델을 단순화(일반화) 시키는 방식
- 통상적으로 GBM에서는 max_depth를 매우 작게 설정하며, 트리 깊이가 5를 넘어가지 않도록 한다
3) 장점과 단점
- 장점
– 성능이 뛰어남
– 패러미터를 많이 튜닝하지 않아도 잘 작동함
– 데이터 스케일링이 필요없다
- 단점
– 매개변수를 잘 조정해야함
– 훈련 시간이 길다
– 텍스트 데이터와 같이 매우 차원이 높고 희소한 데이터에는 잘 작동하지 않음
글을 마치며
머신러닝 모델을 만들 기회가 있을때 주로 사용하던 나무 시리즈를 복습해보았다.
특히 앙상블 모델 위의 2가지는 정말이지 캐글에서도 다른 데이터 분석 대회에서도 default 처럼 고정되어 나오는 모델이다.
그 의미와 기초를 한번 되짚어 보는 기본기 다지기 시간이 된 것 같다.
조만간 해당 모델들이 적용된 사례와 코드를 가지고와서 설명하는 포스팅을 준비해보려한다.
그럼 이만 총총
Comments